By: Joe Block (@curiousbiped)
Edited by: Martin Smith (@martinb3)
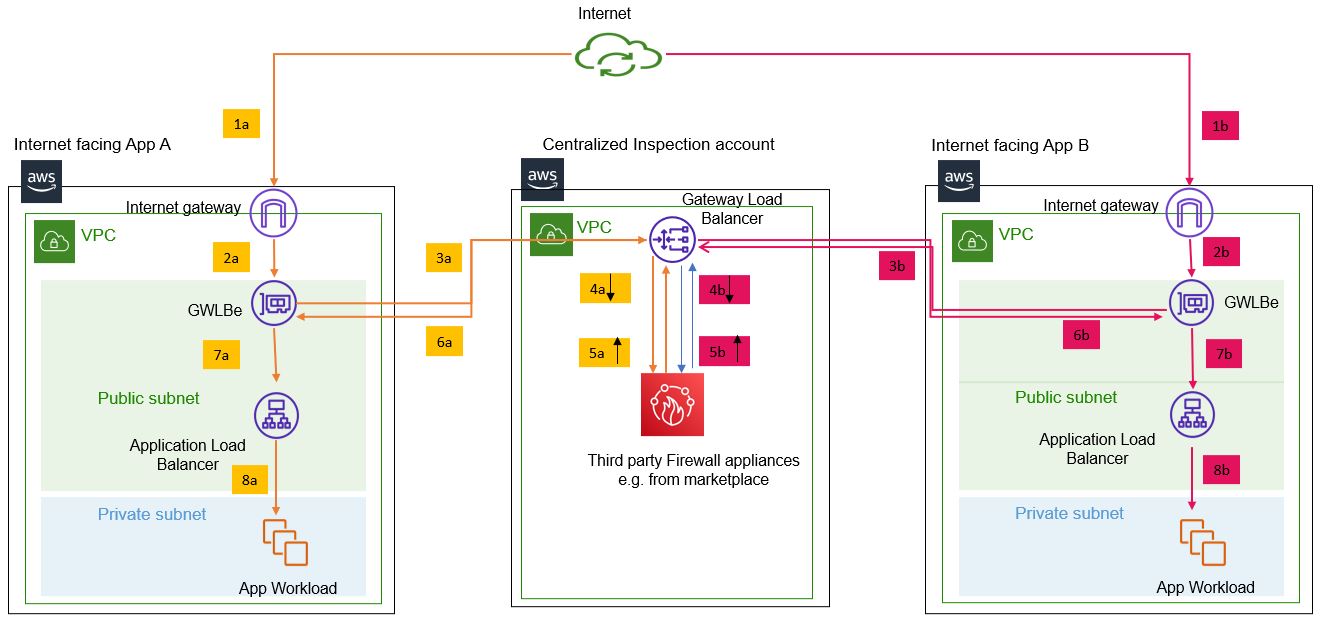
My home lab cluster has a mix of CPU architectures - several Odroid HC2s that are arm7, another bunch of Raspberry Pi 4s and Odroid HC4s that are arm64 and finally a repurposed MacBook Air that is amd64. To further complicate things, they're not even all running the same linux distribution - some run Raspberry Pi OS, one's still on Raspbian, some are running debian (a mix of buster and bullseye), and the MacBook Air runs Ubuntu.
To reduce complication, the services in the cluster are all running in docker or containerd - it's a homelab, so I'm deliberately running multiple options to learn different tooling. This meant that I had to do three separate builds every time I updated one of my images, arm7 , arm64 and amd64, on three different machines, and my service startup scripts all had to determine what architecture they were running on and figure out what image tag to use.
Enter multi-architecture images
It used to be a hassle to create multi-architecture images. You'd have to create an image for each architecture, then upload them all separately from each build machine, then construct a manifest file that included references to all the different architecture images and then finally upload the manifest. This doesn't lead to easy rapid iteration.
Now, thanks to docker buildx, you can create multi-architecture images as easily as docker build creates them for single-architectures.
Let's take a look with an example on my system. First, I can see what architectures are supported with docker buildx ls. As of 2021-12-03, Docker Desktop for macOS supports the following:
NAME/NODE DRIVER/ENDPOINT STATUS PLATFORMS
multiarch * docker-container
multiarch0 unix:///var/run/docker.sock running linux/amd64, linux/arm64, linux/riscv64, linux/ppc64le, linux/s390x, linux/386, linux/mips64le, linux/mips64, linux/arm/v7, linux/arm/v6
desktop-linux docker
desktop-linux desktop-linux running linux/amd64, linux/arm64, linux/riscv64, linux/ppc64le, linux/s390x, linux/386, linux/arm/v7, linux/arm/v6
default docker
default default running linux/amd64, linux/arm64, linux/riscv64, linux/ppc64le, linux/s390x, linux/386, linux/arm/v7, linux/arm/v6
My home lab only has three architectures, so in these examples I'm going to build for arm7, arm64 and amd64.
Create a builder
I need to create a builder that supports multi-architecture builds. This only needs to be done once as Docker Desktop will reuse it for all of my buildx builds.
docker buildx create --name multibuild --use
Building a multi-architecture image
Now, when I build an image with docker buildx, all I have to do is specify a comma-separated list of desired platforms with --platform. Behind the scenes, Docker Desktop will fire up QEMU virtual machines for each architecture I specified, run the image builds in parallel, then create the manifest and upload everything.
As an example, I have a docker image, unixorn/unixorn-py3 that I use for my python projects that installs a minimal Python 3 onto debian 11-slim.
I build it with docker buildx build --platform linux/amd64,linux/arm/v7,linux/arm64 --push -t unixorn/debian-py3 resulting in the output below showing that it's building all three architectures.
❯ rake buildx
Building unixorn/debian-py3
docker buildx build --platform linux/amd64,linux/arm/v7,linux/arm64 --push -t unixorn/debian-py3 .
[+] Building 210.4s (17/17) FINISHED
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 571B 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [linux/arm64 internal] load metadata for docker.io/library/debian:11-slim 3.7s
=> [linux/arm/v7 internal] load metadata for docker.io/library/debian:11-slim 3.6s
=> [linux/amd64 internal] load metadata for docker.io/library/debian:11-slim 3.6s
=> [auth] library/debian:pull token for registry-1.docker.io 0.0s
=> [auth] library/debian:pull token for registry-1.docker.io 0.0s
=> [auth] library/debian:pull token for registry-1.docker.io 0.0s
=> [linux/arm64 1/2] FROM docker.io/library/debian:11-slim@sha256:656b29915fc8a8c6d870a1247aad7796ce296729b0ae95e168d1cfe30dd2fb3c 4.4s
=> => resolve docker.io/library/debian:11-slim@sha256:656b29915fc8a8c6d870a1247aad7796ce296729b0ae95e168d1cfe30dd2fb3c 0.0s
=> => sha256:968621624b326084ed82349252b333e649eaab39f71866edb2b9a4f847283680 30.06MB / 30.06MB 2.0s
=> => extracting sha256:968621624b326084ed82349252b333e649eaab39f71866edb2b9a4f847283680 2.4s
=> [linux/amd64 1/2] FROM docker.io/library/debian:11-slim@sha256:656b29915fc8a8c6d870a1247aad7796ce296729b0ae95e168d1cfe30dd2fb3c 4.0s
=> => resolve docker.io/library/debian:11-slim@sha256:656b29915fc8a8c6d870a1247aad7796ce296729b0ae95e168d1cfe30dd2fb3c 0.0s
=> => sha256:e5ae68f740265288a4888db98d2999a638fdcb6d725f427678814538d253aa4d 31.37MB / 31.37MB 1.8s
=> => extracting sha256:e5ae68f740265288a4888db98d2999a638fdcb6d725f427678814538d253aa4d 2.2s
=> [linux/arm/v7 1/2] FROM docker.io/library/debian:11-slim@sha256:656b29915fc8a8c6d870a1247aad7796ce296729b0ae95e168d1cfe30dd2fb3c 4.3s
=> => resolve docker.io/library/debian:11-slim@sha256:656b29915fc8a8c6d870a1247aad7796ce296729b0ae95e168d1cfe30dd2fb3c 0.0s
=> => sha256:ba82a1312e1efdcd1cc6eb31cd40358dcec180da31779dac399cba31bf3dc206 26.57MB / 26.57MB 2.3s
=> => extracting sha256:ba82a1312e1efdcd1cc6eb31cd40358dcec180da31779dac399cba31bf3dc206 2.0s
=> [linux/amd64 2/2] RUN apt-get update && apt-get install -y apt-utils ca-certificates --no-install-recommends && apt-get upgrade -y --no-install-r 22.3s
=> [linux/arm/v7 2/2] RUN apt-get update && apt-get install -y apt-utils ca-certificates --no-install-recommends && apt-get upgrade -y --no-install 176.9s
=> [linux/arm64 2/2] RUN apt-get update && apt-get install -y apt-utils ca-certificates --no-install-recommends && apt-get upgrade -y --no-install- 173.6s
=> exporting to image 25.4s
=> => exporting layers 6.7s
=> => exporting manifest sha256:ae5a5dcfe0028d32cba8d4e251cd7401c142023689a215c327de8bdbe8a4cba4 0.0s
=> => exporting config sha256:48f97d6d8de3859a66625982c411f0aab062722a3611f18366ecff38ac4eafb9 0.0s
=> => exporting manifest sha256:fc7ad1e5f48da4fcb677d189dbc0abd3e155baf8f50eb09089968d1458fdcfb9 0.0s
=> => exporting config sha256:60ced8a7d9dc49abbbcd02e7062268fdd2f14d9faedcb078b2980642ae959c3b 0.0s
=> => exporting manifest sha256:8f96f20d75502d5672f1be2d9646cbc5d5de3fcffd007289a688185714515189 0.0s
=> => exporting config sha256:0c6e42f87110443450dbc539c97d99d3bfdd6dd78fb18cfdb0a1e3310f4c8615 0.0s
=> => exporting manifest list sha256:9133393fcebf2a2bdc85a6b7df34fafad55befa58232971b1b963d2ba0209efa 0.0s
=> => pushing layers 17.2s
=> => pushing manifest for docker.io/unixorn/debian-py3:latest@sha256:9133393fcebf2a2bdc85a6b7df34fafad55befa58232971b1b963d2ba0209efa 1.4s
=> [auth] unixorn/debian-py3:pull,push token for registry-1.docker.io 0.0s
=> [auth] unixorn/debian-py3:pull,push token for registry-1.docker.io 0.0s
docker pull unixorn/debian-py3
Using default tag: latest
latest: Pulling from unixorn/debian-py3
e5ae68f74026: Already exists
86834dffc327: Pull complete
Digest: sha256:9133393fcebf2a2bdc85a6b7df34fafad55befa58232971b1b963d2ba0209efa
Status: Downloaded newer image for unixorn/debian-py3:latest
docker.io/unixorn/debian-py3:latest
1.60s user 1.05s system 1% cpu 3:36.49s total
One minor issue - docker buildx has a separate cache that it builds the images in, so when you build, the images won't be loaded in your local docker/containerd environment. If you want to have the image in your local docker environment, you need to run buildx with --load instead of --push.
In this example, instead of running docker run unixorn/debian-py3:amd64, docker run unixorn/debian-py3:arm7 or docker run unixorn/debian-py3:arm64 based on what machine I'm on, now I can use the same image reference on all the machines -
❯ docker run unixorn/debian-py3 python3 --version
Python 3.9.2
❯
Takeaway
If you're running a mix of architectures in your lab environment, docker buildx will simplify things considerably.
No more maintaining multiple architecture tags, no more having to build on multiple machines, no more accidentally forgetting to update one of the tags so that things are mysteriously different on just some of our machines, no more weird issues because we forgot to update service start scripts and docker-compose.yml files.
Simpler is always better, and buildx will simplify the environment for you.






 Cloud DMZ: Centralized Inspection Architecture
Cloud DMZ: Centralized Inspection Architecture