By: Bryan Horstmann-Allen (@bdha)
Edited By: Wayne Werner
A small tribe of lost souls finds themselves embattled, after long wandering
the plains of Hell. They nurture a unique Praxis, a small thing. It is not the
making of fire, but it is theirs, with a history that crosses spans of mortal
time. It is precious to them.
They find themselves without the resources to thrive. Hell is harsh, and the
so-called walled heavens of the hyperscalers, closed and proprietary in nature,
consume all within reach.
In this state, a group of Powers acquires the tribe.
The Powers That Were tell them: Your will is ours. Your efforts ours. The
Powers demand global storage clouds. The tribe is ill-equipped for an
undertaking so large. Ramp up time will be required. A single datacenter, they
say – let us build a Proof Of Concept, to identify our gaps, to build our
tooling, to measure twice, and cut once.
There will be no practice, no prototype. Everything will be Production, it will
be done Quickly. The tribe will be oncall 24/7 for empty servers. Failure will
not be countenanced. The Powers claim to build airplanes in the air, change
tires while in motion.
The Powers promises fall like heavy rain: It will be a joint undertaking, the
tribe is told. We will be as One Team.
Eventually these clouds would house roughly an exabyte of data, streaming from
the Aether at 200Gbps, across upwards of 10,000 devices in 20 datacenters.
For the hyperscalers in their false heavens that’s a Tuesday.
For the small tribe, however, new layers of Hell are created from whole clothe.
No Maps For These Territories
The first phase of the project is targeted for an area of the umbral plains
redolent with the monoliths of dozens of datacenter facilities.
Extreme haste is required. The Powers That Were never explain why. Rocks fall
from the skies when progress seems lacking, crushing arbitrary engineers. Speed
is required over all other considerations.
Mistakes will not be made, because they should not be.
The tribe lacks an actual project plan and much needed automation. A
spreadsheet with a dozen lines, like “order hardware,” “install racks” and
“cable up servers,” is provided. It is lacking an attention to detail that
would perhaps prove useful.
The Powers are not Gods, but old, massive, well-funded and long in reach.
The tribe designates internal groups to handle various aspects of the work.
DCOPS, SYSOPS, NETOPS. They daub their foreheads with mud and gather up their
primitive tools.
If the reader is unfamiliar with datacenters, they are actively hostile to
human life. Souls don’t belong there; they are only for machines. Giant
windowless boxes full of smaller screaming sharped-edged boxes. They are loud,
hot and cold. A constant dry wind blows in your face. The lights harsh,
seemingly unending, but if you do not move often enough the entire facility
will be cast into darkness around you.
The longer a soul spends there, the more they lose of themselves. Higher
cognitive functions shut down, memories lost to the patterns of the blinking
lichen.
Mistakes are made, and quickly compounded.
Each team airlifted to the site attempts to complete their work all at once,
dependencies between teams are unclear and regularly consume the fingers of the
unwary. The domes of the cloud balloon above them.
Acolytes of the Powers That Were appear, underfoot, refusing to say why. In
truth, they are there to build their own cloud, adjacent but separate from the
tribes work. The tribe is given no insight, no access, just responsibility. The
Acolytes fail in their work, and the blame is passed on to the tribe.
The Acolytes argue the tribe’s attempts are untenable, they demand that
velocity increase, demand new directions seemingly at random. Progress stalls
as the context switches tear holes in the thin membrane of the local reality.
Screaming horrors slip through and must be contained.
Racks are built in place by Integrator Daemons: servers built on the raised
floor, racked, cabled, nominally tested. Each system trails five network
cables, two power cables, hungry umbilicals ready for sustenance. The USB keys
installed in the rear slots became too hot to touch after a few hours of
screaming operation.
Dead components, shedding their dried scales, are RMA’d through secret,
unknowable means. It can take weeks or months for parts to be replaced.
Souls become lost behind the stacks of discarded cardboard. Some vanish for
good, seemingly burnt away at the edges in the hot exhaust aisle. Those
remaining run out of food, water, sanity.
Engineers gnaw on packing peanuts, simply to make the emptiness inside less.
Each datacenter has to be recabled three times.
The world outside becomes a lie. There is only the facility.
The Director of NETOPS walks alone into the racks. The bear-sized raptors that
infest the high domes of the datacenters can be heard screaming in the voice of
human infants. Their greasy feathers litter the tiles. The Director is never
seen again.
One of the problems you get when dealing with server vendors, integrators,
VARs, whatever, is that the inventory and testing data they give you is never
in a format you want. It is often full of errors, sometimes very subtle ones.
We had scripts to parse PDFs to pull out system inventory data and burn-in
reports. It makes me tired just to think about.
Long after the work has begin, Projections are finally shared by the Powers.
The Powers had demanded 25PB cloud for this quarter. 25PB is built. They
actually needed 60PB. This is clearly the tribes failing, lacking both an
Oracle and having never been given any data from the Powers despite constantly
beseeching Them. All pending builds have similar problems; budgets approved,
hardware purchased. It will not be enough.
Months after the build is “done,” the lost tribe still finds systems with
missing drives, zpools misconfigured; lopsided, keening pathetically. A cascade
of avoidable work follows.
Lessons are learned; none especially technical in nature.
It comes as no surprise that when you give people no time to prepare, no time
to do research or build processes and automation in advance – what you end
up with is a bunch of exhausted people doing subpar work.
Everyone knew what was needed, but no time or resources were allowed to
build any of it properly.
Eventually a demoralized group emerges from under the cloud they had built with
their own bleeding hands. Exhausted, thinner, fewer than when they started.
The cloud runs out of storage.
Like Boulders Up a Hill
The Powers That Were are relentless. The next clouds would be birthed back to
back. The final cloud and the first expansion of the existing regions would be
done in parallel.
It is learned that those amongst the Powers who actually own the data do not
even wish to move it. The Powers That Were bicker amongst themselves. Budgets
are shredded, fluid hissing down from the skies, burning the earth. Timelines
torn. The unknowable Ancients in Finance lay down ultimatums. The clouds must
be built. Costs must be cut. Now.
The Powers settle, once again direct their gaze to the lost souls.
The tribe gets on with it. They know that before they begin the next builds,
they need two things:
Without a detailed project plan and automation to execute it, they would be
stripped of their nerd hoodies and left to the mercies of Hell, alone.
By now, they have directed the Integrator Daemons to build the racks off-site,
in the Daemon’s own facilities, test them, and only then drag the hundreds of
racks into the maw of the cloud. The Integrators will have spares, the
ability to swap out whole chassis, the cost of errors is pushed back on them,
and not onto DCOPS, who are busy contending with the hawkbears.
Information only flows in one direction. They must do their best with suspect
data rarely and only begrudgingly shared.
The first project plan is built in LiquidPlanner. The spreadsheets are set on
fire.
The leads from each of the operating groups sit and gibber at each other for
unknowable hours. The light outside never changes.
At the end, they have a plan with major and minor gates, consisting of some
1500 discrete tasks, all dependencies defined and linked, specific engineers
assigned with worst/best time estimates.
When the Plan needs to change, the timelines shift, realign. The Plan is
flexible. The Plan will be light in the darkness. The Plan will save them.
They cannot be saved. They are already lost.
It can be surprisingly difficult to convince a Project Manager to give up
whatever control they think they possess over the project. When you have
dozens of people working on some incredibly complicated effort, you need to
let the team leads own their work.
The major gates are eldritch concepts:
- Design
- Procurement
- Physical Plant
- …
Portals are built from dead PDU strips, runes engraved with multitools.
The minor gates are interleaved.
- Preflight
- Network I
- Compute I
- Network II
- Compute II
- …
SYSOPS can spin up servers once basic Layer 2 networking is in, and NETOPS has
already moved on to configuring the cross-AZ Layer 3 network. Each datacenter
can be built independently until the final stages.
This interleaving means no particular team is blocked from performing useful
work. The constant movement will keep them warm in the unending dusk.
The automation strategy they settle on is two-fold:
- Validate that what they got is what they bought
- Script every part of building the cloud itself
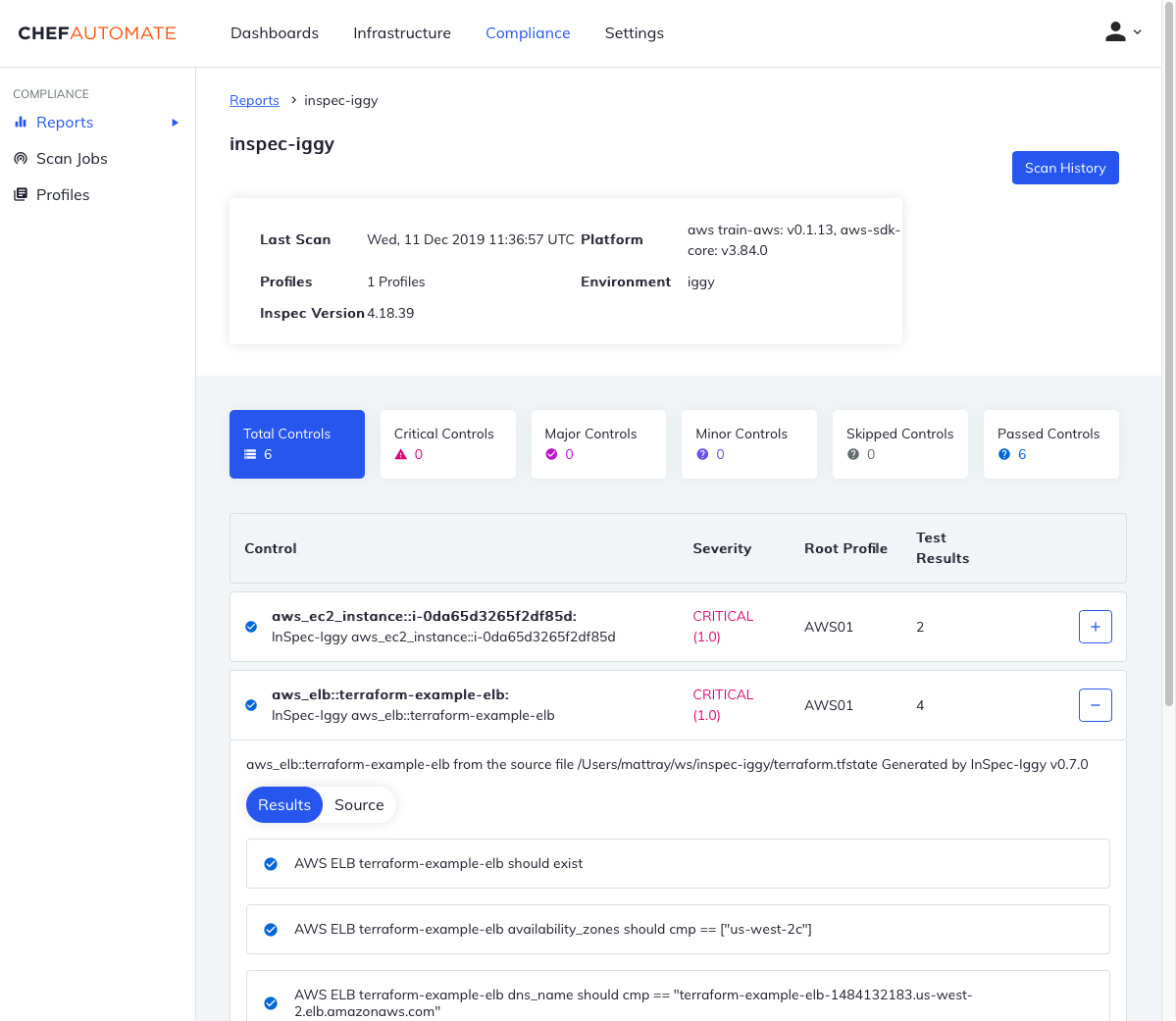
The validation piece is termed “preflight.” The Validator and the
Director of SYSOPS hunt the hawkbears infesting the cloud domes. They push back
on the Powers, usually fruitlessly.
The first version of preflight is a hacked up FAI
deployment, running on a single VM on each of the datacenter management
servers, on a dedicated VLAN.
Once the racks hit the datacenter and the NETOPS shamans bring L2 up, the
servers are PXE booted into a custom rolled live image which runs through a
dozen or so shell scripts.
The scripts dump system inventory to a text file on an NFS mount (this being
Hell), and run basic stress testing. The SYSOPS team provides firmware upgrade
and BIOS configuration tools, which are pushed onto each box.
Scripts are written to validate the system inventory. When errors are found
(like cabling being in the wrong ports) JIRA tickets are cast like bones for
DCOPS to breakfix.
Once a full rack passed preflight, NETOPS is asked to flip the TOR switches
tagged VLAN to production. The servers in the rack are booted and added to a
spreadsheet for the SYSOPS team to provision.
None of this takes very long to implement, which is good because most of it has
to be done during the second cloud build.
There are no resources in the empty plains of Hell for a development lab.
An OPER leaves the tribe.
The Projectionist is cast away by the Powers.
The cloud run out of storage.
The Operationalization Orb
The Validator is catching the majority of initial errors they’d missed on
the first cloud build, but the process is still manual, still tedious. Building
a new cloud takes four to five months.
Manually managing automation incurs errors.
Being exhausted all the time incurs far more errors.
The Validator knew the next version needed to be less 2002 and more modern.
They hunted and felled a database, an API, UI. They wanted the Daemons and
DCOPS and NETOPS and SYSOPS to be able to look at a page that told them exactly
what was wrong with a server
- disk 4 is missing
- missing RAM in slot 2A
- rabid sandtrout caught in thermal shield
- NIC0 should be in port 1:2 but is in 1:3
and so on.
There will be no more JIRA tickets. No more spreadsheets. There is only the
truth they make themselves.
They use the sharpened bones of a hawkbear to carve a schema into the database.
Janky code is written in Perl’s Catalyst. An API and a (pure HTML tables,
natch) UI are birthed.
The builds progress. The Powers That Were can be heard screaming beyond the
veil, demanding more bits, more bandwidth, more flesh. They spew anger and
rage, and the work is made more difficult.
NETOPS run cables from the clouds of the Powers to the heavens. Dozens are
grafted into the domes. Bits stream in from the Aether upwards of 150Gbps. It
is not enough. It will never be enough.
Scaling problems dig their way up from the depths. Drive firmware under heavy
write loads ceases to service reads. This is deemed excellent behavior for the
databases running on them.
Systems reboot themselves, opaque boxes, lying to the tribe’s shamans. A month
passes. Hourly calls every day with the vendor stonewalling. The systems reboot
daily; the cloud chokes on the bits it must be fed. Finally the Powers ordain
they will stop purchasing globally from this vendor unless a solution is found.
A solution is quickly found.
Beastblades Magnetically Aligned
New strong souls are found in the darkness. Their minds are sharp, tools
unmarred. They rewrite preflight, twice. The second time in Mojolicious.
The tribe uses preflight as a source of truth: What is where, what does it do,
is it working, what is wrong with it.
A tool is created for the Command Line, it helps to bring more advocates to the
work. A new web UI is written.
The more hardware-oriented Validators automate PDU and switch configuration.
Improvements are made to testing the CPU, RAM, and disks. Systems are made to
power themselves off multiple times, to try and shock their components into
failing.
The SYSOPS tooling progresses apace. NETOPS gains a new Director and provides
production configs to be burned into the switches during preflight.
Turnkey cloud is near.
A deadline is nearly missed as a vendor fails to schedule air freight to
actually pick up dozens of completed racks. They sit on tarmac for a day.
The tribe is on their fourth Project Manager and second or third VP/Ops.
Everything blurs together. The PM lasts two weeks. The VP a few months.
The Validators devise artifacts that can be placed on top of a freshly squeezed
rack, spinning its servers and reporting back to the API from anywhere on Hell’s
plains. Progress of the rack builds can be viewed live. The servers can be
reached wherever they are, as they are being built, through arcane encrypted
tunnels.
Problems are fixed before the racks ever reach the datacenter. Confidence grows
in what is being delivered. The process is re-run once the racks are installed
in the datacenter. Problems incurred during shipment are quickly repaired. The
number of on-site RMAs plummets to nearly none. Wasted time is regained.
Building a cloud now takes two months. Expansion a few weeks.
The Powers That Were stop the flow of money. They say the cloud is not being
built quickly enough, does not consume quickly enough. They insist the work
continue as they stake the murdered budgets outside the gates of the tribe. The
Powers demand to know why deadlines are missed.
Eventually the money resumes. The tribe has long since learned that their own
actions have little to do with the arbitrary behavior of the Powers.
They are unknowable.
The Insurrection
A lone soul comes in from the darkness. They are admitted, though none of the
women or minority voices among the tribe will be heard. The Powers ignore their
objections, insist again that only Velocity matters. More hands will mean more
results.
This soul immediately argues that the clouds are broken, the tribe is broken.
It will be fine, they know better. They produce nothing but words, but they are
words the Powers want to hear. The tribe is failing purposely, to make the
Powers That Were into the Powers That Will Never Be, out of spite.
Soon the found soul pulls in others, also lost or disaffected from within the
tribe. They argue the Powers are not being appeased quickly enough, not being
fed enough. It is a trick, they wrap their own ambition in devotion.
They cast selfishness as piety. They claim they can build a cloud in a weekend.
They claim they have done it, but show no one. They whisper to anyone who will
listen the tribe is full of morons, the CEO and CTO are fools leading the tribe
to ruin.
These turncoats work in secret; finally discovered: copyright assigned to
themselves and not the tribe, not even the Powers they claim to serve. The
tribe believes these turncoats undone – they surely will be cast away, the
distractions finished.
The turncoats flee to where the Powers reside and a Validator is sent after
them. Irreparable damage is done to the tribe in short order. A duel is
required. The tribe’s Praxis against the turncoats vapor. It is all a sham. The
Powers flexing.
Deeply messed up stuff happens, just like really seriously amazingly dumb
things.
The Powers give the turncoats a place to work, hidden from the rest of the
tribe. The tribe is shocked. The last shreds of morale are found hiding under
a bean bag chair, mourned, set alight, the ashes buried.
Never hire anyone without interviewers of a mix of backgrounds talking to
them first. Listen to your people. Heartbreak can be avoided.
Periodically the priest of these turncoats is sent back into the tribe. He
tells them how great the True Work is going. The tribe is not allowed to see
this work; they are assured it is amazing; the existing clouds are already
obsolete; they should just give up already.
The priest is challenged during an incredibly uncomfortable all-hands. The
Powers intervene. The priest assures the tribe he will always protect them, and
then he leaves. This happens several times. The tribe is dubious. The work
continues.
The CTO is exiled to an island surrounded by clever, insane kappa. He is given
books and has no one to talk to.
The First Validator walks into the darkness, head bent, tools discarded in the
dust.
A year passes. The turncoats unsurprisingly fail miserably. The Powers exile
them. Some of them somehow manage to end up in even worse places, there being
an unending number of just terrible places among the industries of the umbral
plains.
The Powers are finally fed at 200Gbps. They are unsatiated.
The CEO follows so many others into the desert.
The CTO crafts a boat from discarded hopes and sails off.
The clouds sing, bellies full of encrypted baubles from millions of the unseen.
Much of the original tribe is shattered.
The Powers announce they will take their data to another cloud, a better cloud,
a heavenly cloud, and that the tribe will dismantle what they’ve painfully
born.
This does not occur: the false heavens cannot feed them, cannot sustain them.
The work continues.
Post-script
This post brought to you by: three years of 10–16 hour days, a no-notice trip
from MEL to ICN to SFO to MEL in ten days, exponential burnout, foxhole
buddies, and taking an entire year off to recover.
Shout out to all the awesome people who did simply amazing work under the worst
conditions. You know who you are.
We all deserved better.